桌面端、WSL 与 Linux Server 使用手册
这份手册适合什么时候看
Section titled “这份手册适合什么时候看”这页是 Relay Switch 的正式使用说明。
当你希望系统地了解下面这些问题时,优先看这一页:
- 本地网关到底是怎么工作的
- Provider 应该怎么添加和切换
- 工具到底应该怎么接入
- Models 页面里的排序到底什么时候生效
- 请求失败时应该按什么顺序排查
整体流量路径
Section titled “整体流量路径”Relay Switch 位于客户端工具和上游中转 Provider 之间。
一次正常请求的路径通常是:
- 你的工具先把请求发给本地 Relay Switch 地址
- Relay Switch 读取当前激活的 Provider
- Relay Switch 注入上游密钥
- Relay Switch 把请求转发给上游 Provider
- 上游响应再回到你的工具
- 请求过程被记录到本地日志里
这也是为什么你的工具可以始终只配置一个本地入口,而上游切换由桌面应用统一控制。
桌面端与 Web 端的关系
Section titled “桌面端与 Web 端的关系”Relay Switch 现在有两类管理入口:
Electron桌面端Web / PWA补充入口
它们的职责不是对等的。
必须按下面的原则理解:
Electron仍然是本地主入口Web / PWA主要用于WSL和Linux serverWeb / PWA不是桌面端替代品
桌面端继续负责:
- 本地 core 生命周期
- 托盘和窗口
- 本地桌面集成
- 桌面应用更新
Web / PWA 主要负责:
- 在浏览器里管理运行中的 core
- 为无桌面环境提供页面入口
- 为 WSL 和 Linux server 提供更方便的管理体验
WSL 使用方式
Section titled “WSL 使用方式”如果你主要在 WSL 里运行 Codex CLI、Claude Code 或其他命令行工具,推荐这样使用:
- 在
WSL内启动relay-switch-core - 让浏览器访问这个 WSL 实例暴露的地址
- 在 Web 页面中管理
Providers、Models、Logs、Tools
这样做的关键好处是:
- 工具配置文件写入发生在
WSL自己的 Linux 用户目录 - 不需要 Windows 桌面端跨环境替 WSL 写配置
- 一键配置和真实运行环境一致
Linux server 使用方式
Section titled “Linux server 使用方式”如果你把 Relay Switch 跑在 Linux server、云主机、家庭服务器或 NAS 上,推荐这样使用:
- 在目标 Linux 环境中启动
relay-switch-core - 通过浏览器访问该实例暴露的地址
- 在 Web 页面中完成
Providers、Models、Logs、Tools管理
这个模式适合:
- 没有桌面环境的机器
- 持续运行的开发服务器
- 需要在浏览器里远程查看运行状态的场景
PWA 的定位
Section titled “PWA 的定位”如果你在 Chrome 或兼容浏览器中安装了 PWA,需要明确它的定位:
- PWA 只是 Web 管理端的安装形态
- PWA 提供的是“更像应用”的浏览器入口
- PWA 不是 Electron 桌面端的替代品
PWA 可以提供:
- 独立窗口
- 快捷入口
- 静态资源缓存
PWA 不负责:
- 拉起本地 Go core
- 托盘、自启动、桌面通知
- 桌面应用更新
补充入口下的工具一键配置
Section titled “补充入口下的工具一键配置”当你通过 WSL 或 Linux server 的 Web 页面进入 Tools 页时,一键配置会直接作用于当前 core 所在环境。
这意味着:
- 在 WSL 里打开的 Web 页面,会写 WSL 里的
~/.codex、~/.claude - 在 Linux server 里打开的 Web 页面,会写 server 自己的用户目录
这也是为什么 Web 端更适合作为 WSL 和 Linux server 的补充入口。
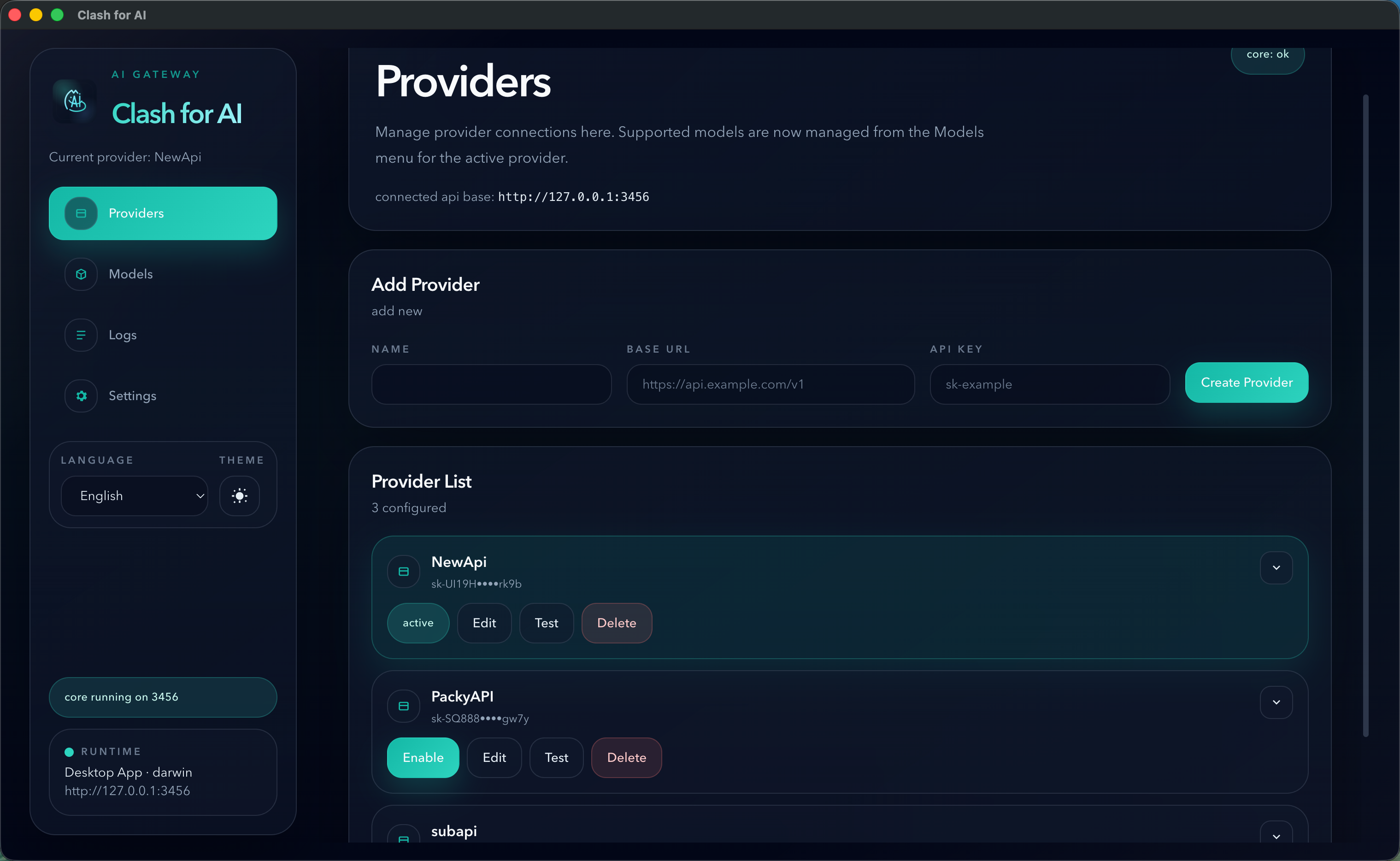
Provider 配置检查清单
Section titled “Provider 配置检查清单”添加 Provider 时,重点确认这三个字段:
NameBase URLAPI Key
对于 OpenAI 兼容中转服务,最稳妥的 Base URL 通常是带 /v1 的地址。
例如:
https://example.com/v1https://api.example.com/v1如果服务商文档只给了根域名,而模型列表获取失败,建议再尝试一次带 /v1 的写法。
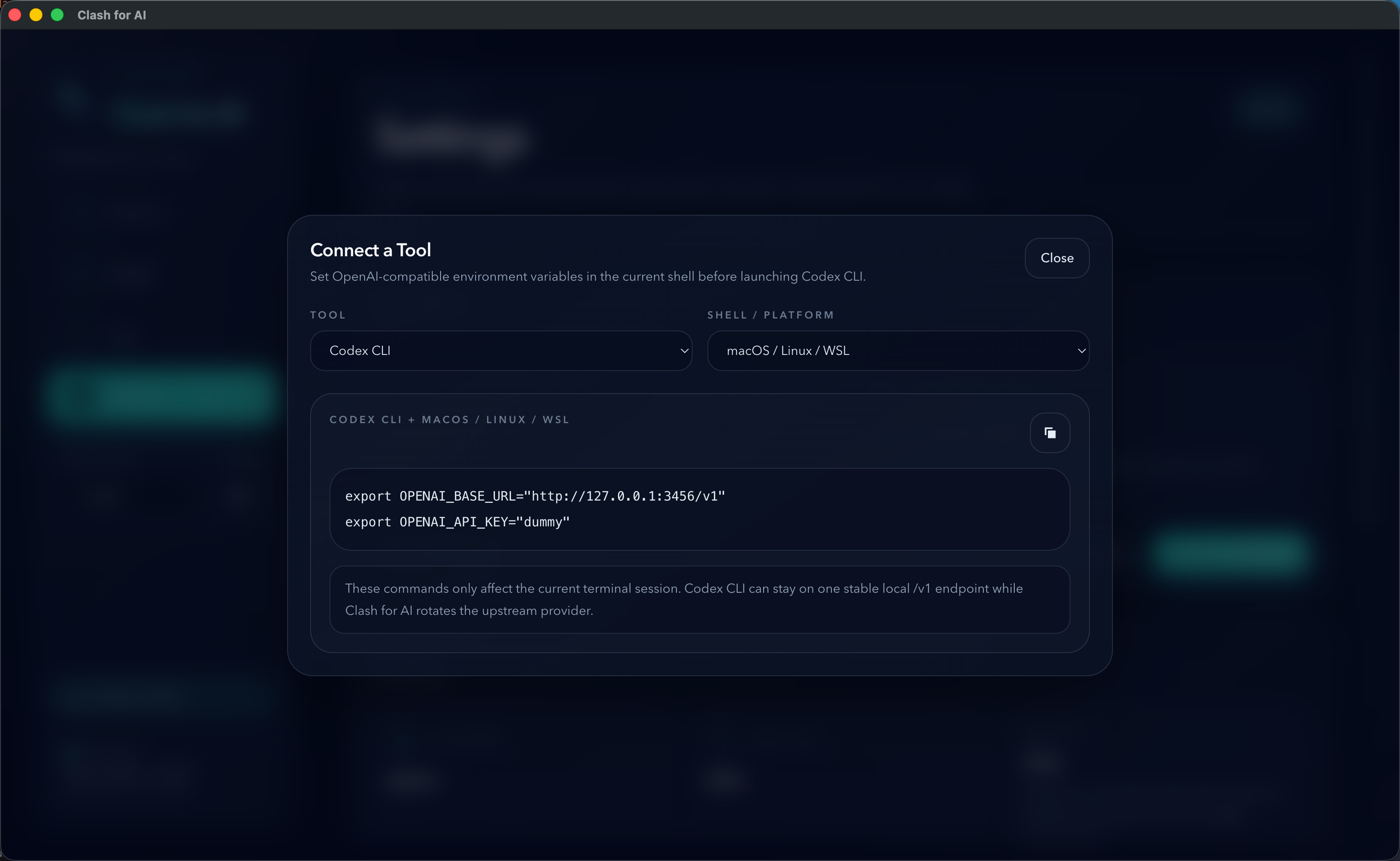
工具接入检查清单
Section titled “工具接入检查清单”对于大多数 OpenAI 兼容客户端,最简接入方式是:
Base URL: http://127.0.0.1:3456/v1API Key: dummy如果应用里显示的实际端口不是 3456,请以桌面应用中的 connected api base 为准。
Models 页面到底什么时候生效
Section titled “Models 页面到底什么时候生效”Models 页面不会替用户主控选择模型。
真正决定请求哪个模型的,仍然是客户端工具本身。
Relay Switch 里的已选模型排序,只会在这些条件下生效:
- 当前请求是 JSON 格式的
POST - 请求体里本身已经有
model字段 - 这个模型已经命中 Relay Switch 的已选模型列表
- 上游请求失败,且错误属于可重试条件,比如
429、5xx或网络错误
如果请求模型不在已选列表中,Relay Switch 不会自动切换到其他备用模型。
关于模型列表获取的说明
Section titled “关于模型列表获取的说明”模型列表获取是一个“兼容性增强能力”,不是所有中转服务都保证支持的能力。
常见失败原因包括:
- 服务商根本不暴露模型发现接口
- 服务商只支持
/v1/models - 服务商返回的 JSON 不是标准 OpenAI 风格
- 服务商使用的是当前项目还不支持的原生协议
所以如果某个 Provider 请求能正常转发,但模型列表获取失败,这更像是“模型发现兼容性问题”,不一定代表这个 Provider 本身不可用。
推荐排查顺序
Section titled “推荐排查顺序”当请求异常时,建议按这个顺序查:
- 确认本地 core 是否正常运行
- 查看桌面应用里的
connected api base - 先跑 provider healthcheck
- 重点确认 Base URL,尤其是否需要
/v1 - 打开日志页,看上游返回的错误正文
- 用一个已知兼容的 OpenAI 客户端复现同样的 Provider 配置
当前协议范围
Section titled “当前协议范围”Relay Switch 当前主要面向:
- OpenAI 兼容上游
- Anthropic 兼容上游
Gemini 原生协议当前还不是一等上游协议。
- 查看 Providers 了解兼容性说明
- 查看 工具接入 了解客户端接入方式
- 查看 Deep Link 导入 了解如何从网页唤起桌面应用并预填导入配置
- 查看 FAQ 了解模型和 fallback 相关问题